4M.4.FULLSTACKS: Cross-stack Compute
Table of Contents
- Quickstart Tutorial
- Introduction
- Use of Globus Auth Token
- Globus Genomics WES Interface
- Analysis of 5 Downsampled CRAM inputs
Quickstart Tutorial
This quickstart tutorial walks through a quick submission of 5 downsampled TOPMed CRAM input files using a TOPMed Alignment workflow in CWL. It uses a portal to index and search the input datasets and submits to a WES (Workflow Execution Service - GA4GH) service deployed as a shim-layer on the Galaxy based Globus Genomics platform.
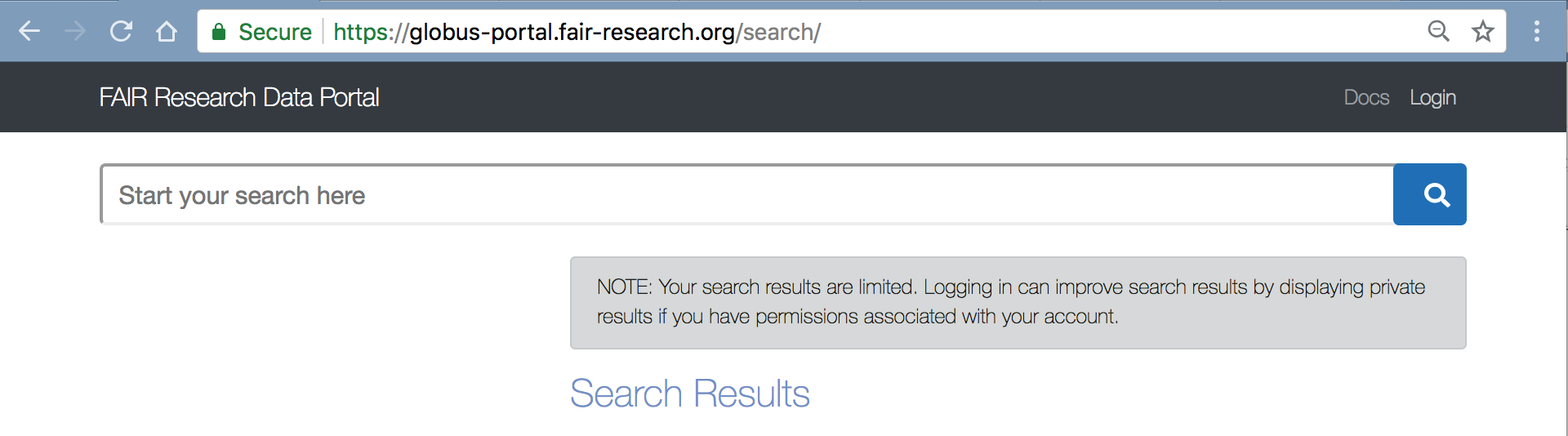
- Login to the search portal at: https://globus-portal.fair-research.org/search/ using your Globus credentials
- Search for the 5 downsampled input CRAM files using the search tag “downsampled”
- Select the 5 samples by checking the box next to “downsampled” in the left menu
- Click on “Add Minids” button, which creates a Workspace called “Downsampled Topmed” and adds these 5 samples for analysis
- Then click on the “Start” button for each input CRAM file to initiate the alignment workflow using Globus Genomics backend.
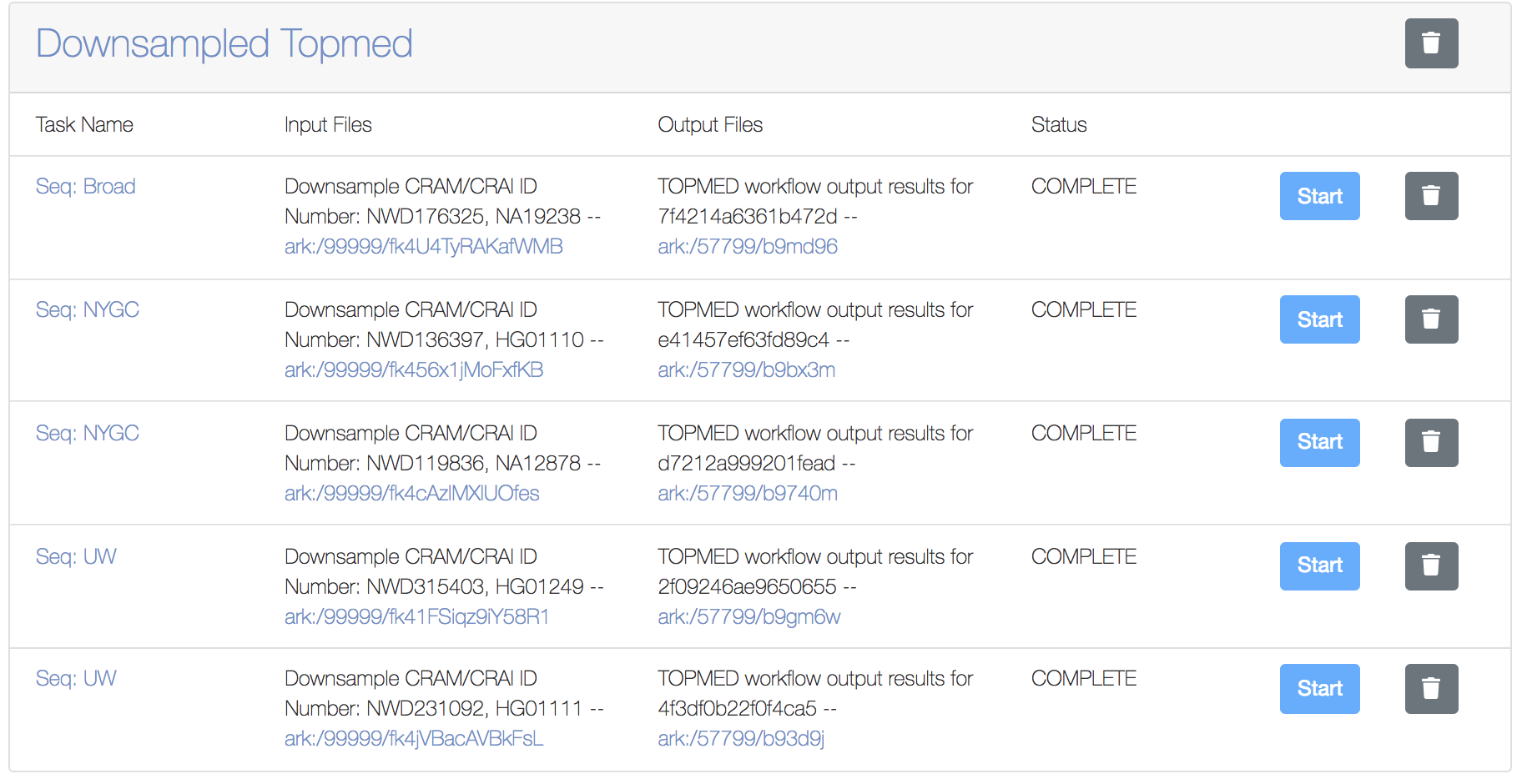
- Typically, after 20-25mins, the analysis of the 5 downsampled inputs should be completed and you should see the resulting BDBag-Minid under the “Output files” column of the workspace. The picture below shows a screenshot of the workspace used for the analysis of the 5 input CRAM files
Introduction
This README describes the implementation of a fullstacks platform that allows to:
- Analyze open access TOPMed WGS data by sharing the same CWL workflow around with other fullstacks
- Scale up the analysis to 5 downsampled, 7 full size WGS open access TOPMed samples and 25 of the remaining 100 samples
- Demonstrate the use of GA4GH Workflow Execution Service (WES) implementation to standardize the workflow execution across multiple fullstacks
- Build upon the “Workspaces” implemented in 3M.4 Fullstacks demo and add additional features to submit to the WES interface
- Use of Globus auth tokens for user access and user management in Galaxy within Globus Genomics
Some of the highlights of this month’s deliverable are:
- We indexed the 5 downsampled and 107 open access TOPMed samples within the data portal at https://globus-portal.fair-research.org/workflows/
- We implemented a CWL-Runner tool within Galaxy to support CWL workflow execution within Galaxy based Globus Genomics
- We implemented a GA4GH WES service that provides a standard interface to allow CWL based workflow submission and workflow status tracking hiding the Galaxy specific details
- A major feature is the use of Globus auth tokens for user-management on the Galaxy side, thus eliminating the need for a Galaxy API keys used in the previous month deliverables
- Extended the fair research data portal to act as an workflow orchestrator to submit CWL workflows to Globus Genomics via the new WES interface
Use of Globus Auth Token:
One of the highlights of this deliverable is the use of Globus Auth tokens instead of the Galaxy API Keys to interact with Galaxy. Within the WES implementation, the Globus auth token is used to map the user to the local Galaxy user. If the user doesn’t exist, from within the WES, we create that user using the Galaxy Bioblend API and generate a Galaxy API Key that is then used internally. If the user already exists, we map the Globus Auth token to the user and retrieve the API key and use it to interact with Galaxy. It significantly simplifies the authentication, authorization and the ease of use of our fullstacks platform.
We demonstrate this feature by using the data portal that uses Globus authentication to login. And the portal submits the CWL workflows to the WES interface with the Globus auth tokens in the headers that have the Globus Genomics application scope for further validation.
Globus Genomics WES Interface
GA4GH specifications for the Workflow Execution Service is available as Swagger UI at: http://ga4gh.github.io/workflow-execution-service-schemas/ The Globus Genomics WES service is implemented to the above specification and the available at: https://nihcommons.globusgenomics.org/wes/service-info
The resources implemented in this WES are:
- GET: /service-info
- GET: /workflows
- POST: /workflows
- GET: /workflows/
- DELETE: /workflows/
- GET: /workflows/
/status
Detailed descriptions and usage of each resource is available at: http://ga4gh.github.io/workflow-execution-service-schemas/
Analysis of 5 Downsampled CRAM inputs
Using Data Portal
User Login to FAIR Research Data Portal
The FAIR Research data portal is available at: https://globus-portal.fair-research.org and users can login using the Login link in the top-right corner.
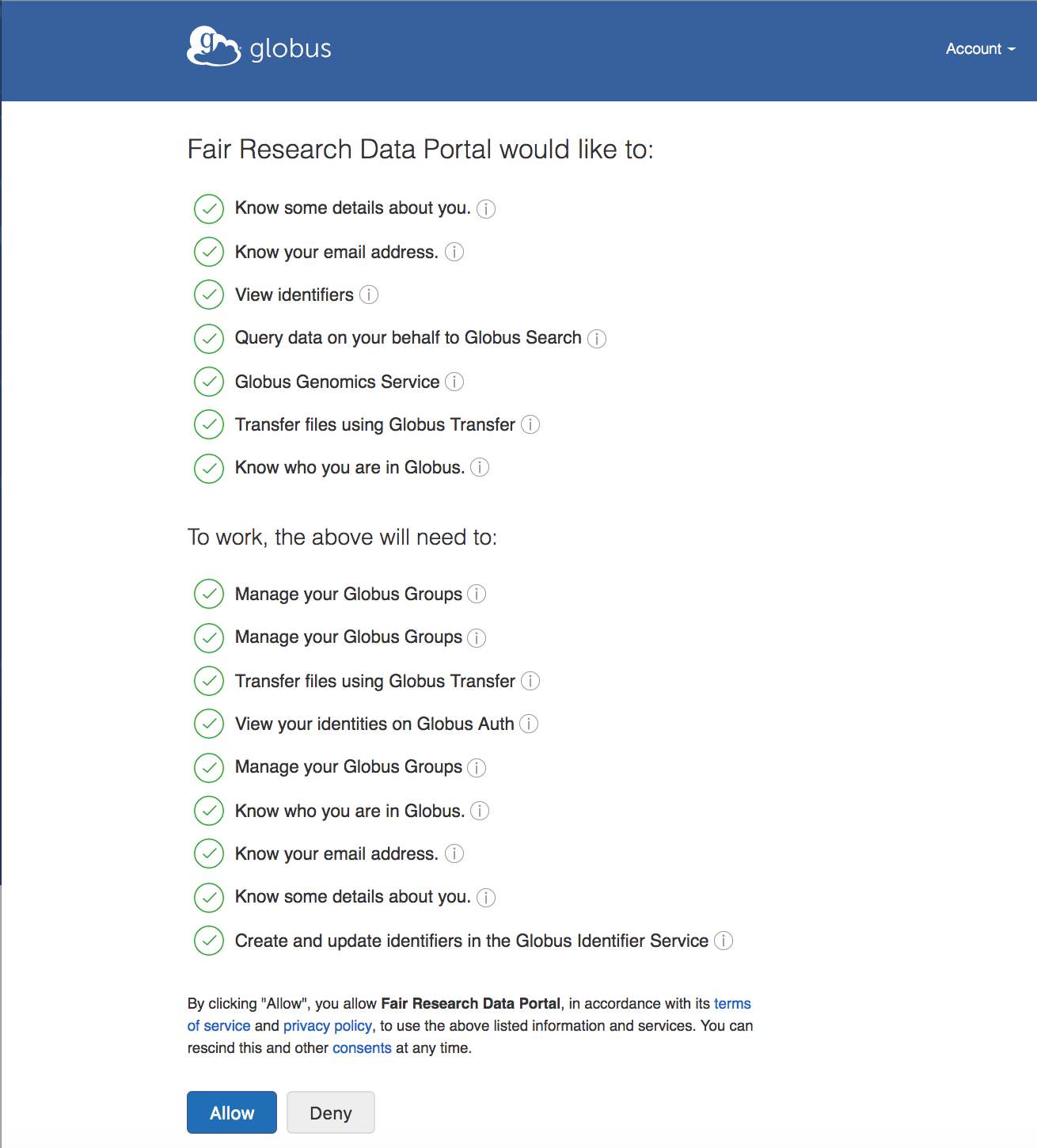
When asked for the consent, please allow the portal to access the information and services listed. You will notice that you are also allowing access to the Globus Genomics service. The scope to use Globus Genomics is added to the Auth token generated by Globus, which will be presented by the portal to the WES service within Globus Genomics.
Search
The downsampled CRAM files have an annotation of “downsampled” within the data portal. Use the search term “downsampled” in the search box at: https://globus-portal.fair-research.org/search/
Select the checkbox next to “downsampled” in the left hand menu as shown in the screenshot below.
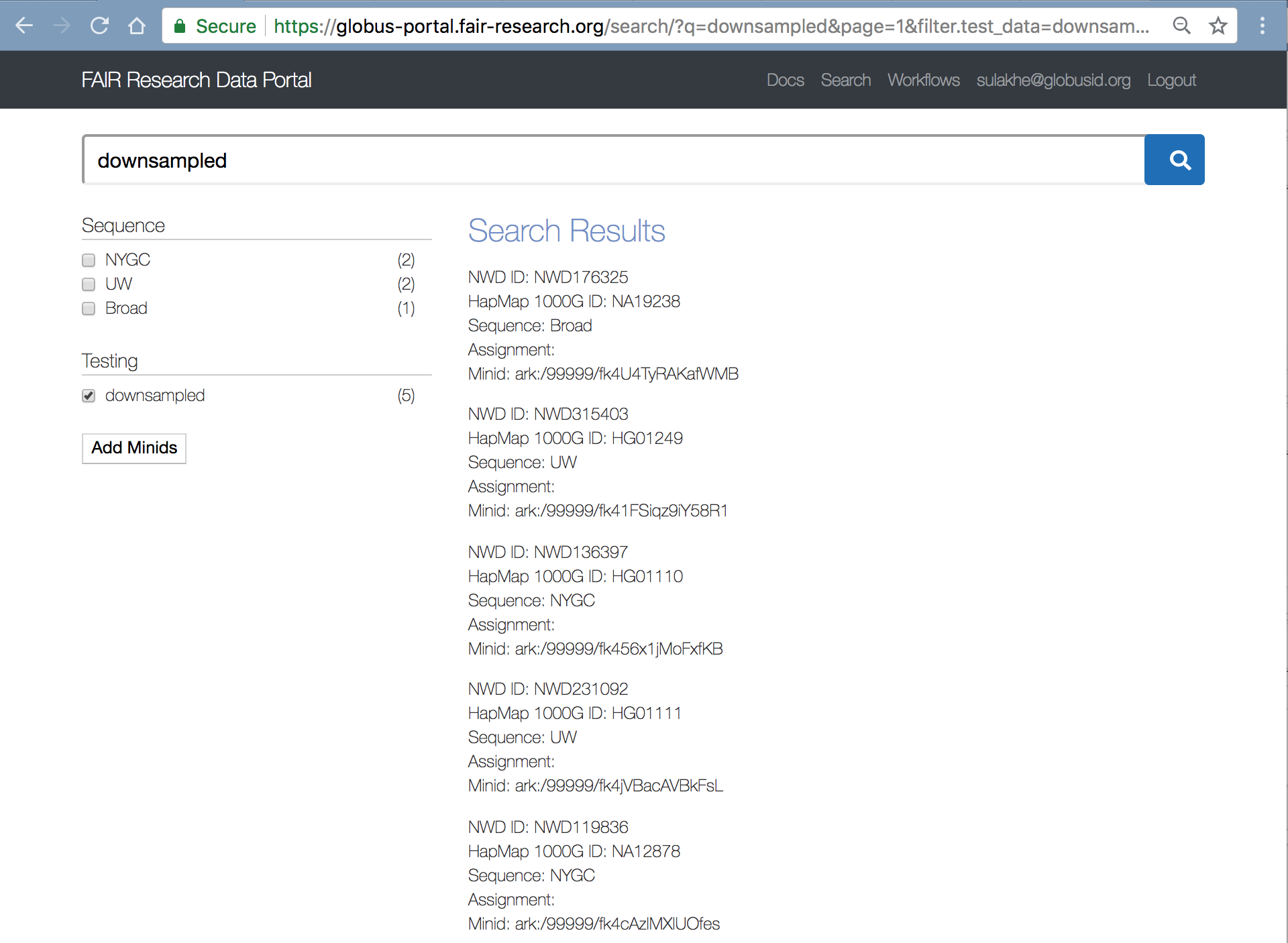
Click on the “Add Minids” button to add the 5 samples to a “Workspace” collection called “Downsampled Topmed” as shown below.
Submit
From within the Workspace, click on each “Start” button to initiate a submission to the WES service.
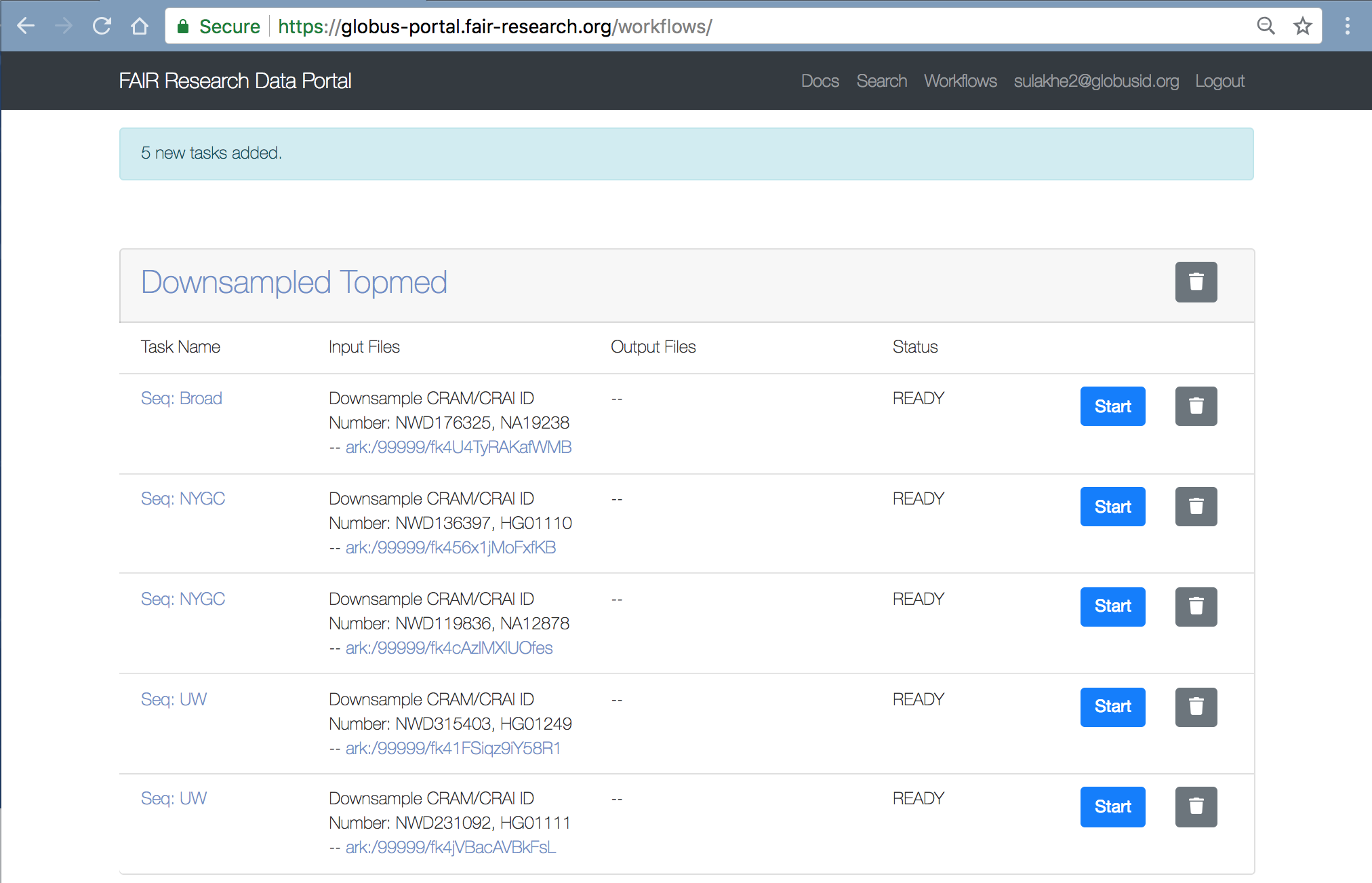
Status
These downsampled CRAMs, typically take about 20-25mins to complete the analysis. Once the analysis is complete, you will notice the status in Workspace changes to “Complete” and you should also see the MINID for the output BDBag generated. The screenshot below shows a completed analysis:
Using CURL from command line
Get Globus Token
The WES API exists as a public Resource Server secured with Globus Auth, so you may request a token and submit samples using any registered Globus app.
Starting from scratch requires three steps:
- Register a Globus App at https://developers.globus.org
- Configure your app to request the NIH Commons scope
- Login to receive your token
JSON Payloads
For each of the 5 downsampled CRAM inputs, the three reference files (reference_genome, bwa_index and dbsnp) will be same. Please note the minids for these 3 reference files within the JSON payload example below
The input minids for the 5 downsampled CRAMs are:
- Downsample CRAM/CRAI ID Number: NWD176325, NA19238 – ark:/99999/fk4U4TyRAKafWMB
- Downsample CRAM/CRAI ID Number: NWD136397, HG01110 – ark:/99999/fk456x1jMoFxfKB
- Downsample CRAM/CRAI ID Number: NWD119836, NA12878 – ark:/99999/fk4cAzlMXIUOfes
- Downsample CRAM/CRAI ID Number: NWD315403, HG01249 – ark:/99999/fk41FSiqz9iY58R1
- Downsample CRAM/CRAI ID Number: NWD231092, HG01111 – ark:/99999/fk4jVBacAVBkFsL
Below is an example of the JSON payload used to do a POST request to the WES at https://nihcommons.globusgenomics.org/wes/workflows
{
"workflow_params": {
"reference_genome": {
"class": "File",
"path": "ark:/99999/fk4aZVT0ZWH8Ip0"
},
"bwa_index": {
"class": "File",
"path": "ark:/99999/fk4erydOcxk7PA2"
},
"dbsnp": {
"class": "File",
"path": "ark:/99999/fk4zKBK8XkAnaXQ"
},
"input_file": {
"class": "File",
"path": "ark:/99999/fk4U4TyRAKafWMB"
}
},
"workflow_descriptor": "TOPMed Alignment Workflow",
"workflow_url": "https://raw.githubusercontent.com/DataBiosphere/topmed-workflows/master/aligner/sbg-alignment-cwl/topmed-alignment.cwl",
"workflow_type_version": "v1.0",
"workflow_type": "CWL"
}
CURL Commands
Here are the 5 command-line curl statements for submitting the 5 Downsampled CRAM input files. Replace the <TOKEN> with the token generated in the previous section:
Downsample CRAM/CRAI ID Number: NWD176325, NA19238:
curl -H "Accept: application/json" -H "Content-Type: application/json" -X POST -H "Authorization: <TOKEN>" '{"workflow_params": {"reference_genome": {"class": "File", "path": "ark:/99999/fk4aZVT0ZWH8Ip0"}, "bwa_index": {"class": "File", "path": "ark:/99999/fk4erydOcxk7PA2"}, "dbsnp": {"class": "File", "path": "ark:/99999/fk4zKBK8XkAnaXQ"}, "input_file": {"class": "File", "path": "ark:/99999/fk4U4TyRAKafWMB"}}, "workflow_descriptor": "TOPMed Alignment Workflow", "workflow_url": "https://raw.githubusercontent.com/DataBiosphere/topmed-workflows/master/aligner/sbg-alignment-cwl/topmed-alignment.cwl", "workflow_type_version": "v1.0", "workflow_type": "CWL"}' https://nihcommons.globusgenomics.org/wes/workflows
Downsample CRAM/CRAI ID Number: NWD315403, HG01249:
curl -H "Accept: application/json" -H "Content-Type: application/json" -X POST -H "Authorization: <TOKEN>" '{"workflow_params": {"reference_genome": {"class": "File", "path": "ark:/99999/fk4aZVT0ZWH8Ip0"}, "bwa_index": {"class": "File", "path": "ark:/99999/fk4erydOcxk7PA2"}, "dbsnp": {"class": "File", "path": "ark:/99999/fk4zKBK8XkAnaXQ"}, "input_file": {"class": "File", "path": "ark:/99999/fk41FSiqz9iY58R1"}}, "workflow_descriptor": "TOPMed Alignment Workflow", "workflow_url": "https://raw.githubusercontent.com/DataBiosphere/topmed-workflows/master/aligner/sbg-alignment-cwl/topmed-alignment.cwl", "workflow_type_version": "v1.0", "workflow_type": "CWL"}' https://nihcommons.globusgenomics.org/wes/workflows
Downsample CRAM/CRAI ID Number: NWD136397, HG01110:
curl -H "Accept: application/json" -H "Content-Type: application/json" -X POST -H "Authorization: <TOKEN>" '{"workflow_params": {"reference_genome": {"class": "File", "path": "ark:/99999/fk4aZVT0ZWH8Ip0"}, "bwa_index": {"class": "File", "path": "ark:/99999/fk4erydOcxk7PA2"}, "dbsnp": {"class": "File", "path": "ark:/99999/fk4zKBK8XkAnaXQ"}, "input_file": {"class": "File", "path": "ark:/99999/fk456x1jMoFxfKB"}}, "workflow_descriptor": "TOPMed Alignment Workflow", "workflow_url": "https://raw.githubusercontent.com/DataBiosphere/topmed-workflows/master/aligner/sbg-alignment-cwl/topmed-alignment.cwl", "workflow_type_version": "v1.0", "workflow_type": "CWL"}' https://nihcommons.globusgenomics.org/wes/workflows
Downsample CRAM/CRAI ID Number: NWD231092, HG01111:
curl -H "Accept: application/json" -H "Content-Type: application/json" -X POST -H "Authorization: <TOKEN>" '{"workflow_params": {"reference_genome": {"class": "File", "path": "ark:/99999/fk4aZVT0ZWH8Ip0"}, "bwa_index": {"class": "File", "path": "ark:/99999/fk4erydOcxk7PA2"}, "dbsnp": {"class": "File", "path": "ark:/99999/fk4zKBK8XkAnaXQ"}, "input_file": {"class": "File", "path": "ark:/99999/fk4jVBacAVBkFsL"}}, "workflow_descriptor": "TOPMed Alignment Workflow", "workflow_url": "https://raw.githubusercontent.com/DataBiosphere/topmed-workflows/master/aligner/sbg-alignment-cwl/topmed-alignment.cwl", "workflow_type_version": "v1.0", "workflow_type": "CWL"}' https://nihcommons.globusgenomics.org/wes/workflows
Downsample CRAM/CRAI ID Number: NWD119836, NA12878:
curl -H "Accept: application/json" -H "Content-Type: application/json" -X POST -H "Authorization: <TOKEN>" '{"workflow_params": {"reference_genome": {"class": "File", "path": "ark:/99999/fk4aZVT0ZWH8Ip0"}, "bwa_index": {"class": "File", "path": "ark:/99999/fk4erydOcxk7PA2"}, "dbsnp": {"class": "File", "path": "ark:/99999/fk4zKBK8XkAnaXQ"}, "input_file": {"class": "File", "path": "ark:/99999/fk4cAzlMXIUOfes"}}, "workflow_descriptor": "TOPMed Alignment Workflow", "workflow_url": "https://raw.githubusercontent.com/DataBiosphere/topmed-workflows/master/aligner/sbg-alignment-cwl/topmed-alignment.cwl", "workflow_type_version": "v1.0", "workflow_type": "CWL"}' https://nihcommons.globusgenomics.org/wes/workflows
These curl commands return a tracking ID (workflow-id) that can be used to check the status, as shown in the next section.
Check Status
The WES resources for a detailed status, also provides the MINDs for the output BDBag once the analysis is complete. You can
curl -H "Accept: application/json" -H "Content-Type: application/json" -X GET -H "Authorization: <TOKEN>" https://nihcommons.globusgenomics.org/wes/workflows/<workflow-id>
Results
Following table provides the results of analysis with md5sum for the output, along with time taken and cost of analysis. Please note that the md5sum are calculated after removing the headers from the output CRAM file, so that the md5sum can be compared with the results from other fullstacks.
| Downsample Inputs | md5sum | Runtime | Cost($) |
|---|---|---|---|
| NWD119836 | 105bf65c2e4ea23f7a110bee17c1a074 | 19mins | 0.036 |
| NWD136397 | c8bab3ba0f90406a035cabb243716356 | 19mins | 0.036 |
| NWD176325 | 186d2cdf1efdc2746e6d3b26cd887c0a | 19mins | 0.036 |
| NWD231092 | 4ac1e5edc1fd9d0644d2c0082ac02392 | 19mins | 0.036 |
| NWD315403 | efda0cdef1e172f495052a62a93d799c | 19mins | 0.036 |
This work was supported in part by NIH grant 1U54EB020406-01.